지난 50년 간 인공지능은 부침의 역사를 겪으며 발전했으며, 딥러닝으로 촉발된 세 번째 황금기는 제4차 산업혁명을 견인
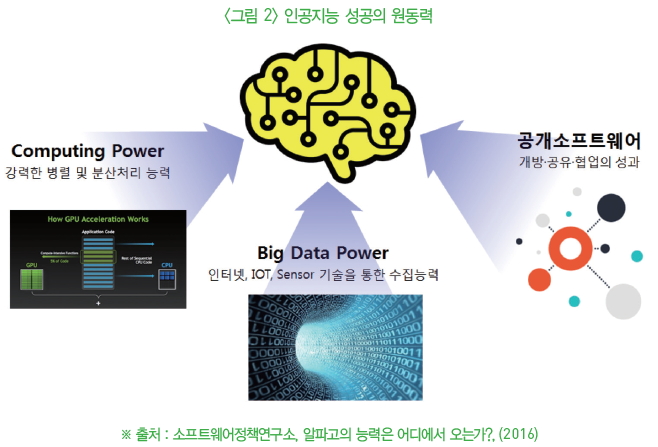
최근 인공지능의 성공요인은 막대한 컴퓨팅 파워, 공개 SW의 확산, 빅데이터의 보급
인공지능의 역사
인공지능(Artificial Intelligence, AI)는 인간의 지능적 행동을 모사하여 자동화하는 컴퓨터 과학의 한 분야
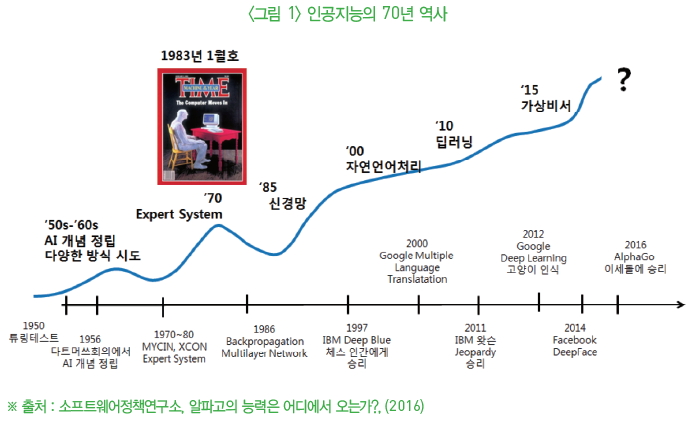
인공지능은 두 번의 황금기와 암흑기를 거쳐, 세 번째 황금기를 맞이함
1956년 : 인공지능의 대부 존 매카시가 개최한 다트머스 회의에서 인공지능에 대한 정의와 개념을 정립하면서 인간의 지능을 대체할 학문분야로 인정
1970년(첫 번째 황금기) : 특정 분야에 전문적인 지식을 탑재한 전문가 시스템(Expert System)에 막대한 연구자금이 투입
• 1980년대 중반(첫 번째 암흑기) : 그러나 전문가 시스템이 목표문제를 해결하지 못함에 따라 인공지능에 대한 뜨거운 관심이 약화
1985년(두 번째 황금기) : 인공신경망의 한 종류인 다층 퍼셉트론(Multi-Layer Perceptron)의 학습방법인 오류역전파법(Error Back-propagation Method)이 지능적 문제를 해결할 수 있는 가능성 제시
• 2000년대 중반(두 번째 암흑기) : 세간의 조명을 받았던 오류역전파법 역시 제한적인 데이터, 컴퓨팅파워 부족 등 물리적인 한계로 인해 빛을 발하지 못함
2006년(세 번째 황금기) : 인공지능의 부침의 역사에도 불구하고 지속적으로 연구를 수행한 토론토 대학의 제프리 힌튼 교수는 인공신경망의 혁신적인 학습 기법인 자율 학습(unsupervised learning)을 발표
• 기존 인공신경망의 학습 방법은 초기 값에 대한 의존성이 매우 크기 때문에 새로 학습할 때마다 일정하지 않은 결과가 나타나고, 인공신경망이 깊어(deep)질수록 더 큰 폭의 차이가 발생
• 이러한 한계를 극복한 것이 자율 학습으로, 데이터에 해당하는 정보(label)가 없어도 학습할 수 있고 나아가 자율 학습 결과를 초기 값으로 활용하여 일관성 있는 학습 결과 도출
• 구글의 인공지능 프로젝트인 구글 브레인(Google Brain)에서 사용된 기법이 자율 학습으로, 유튜브 영상에서 고양이라는 정보 없이 고양이를 인식하고 분류하는데 성공
현재의 인공지능은 이미지 인식, 필기 인식, 음성 인식, 영어의 자연어 처리가 가장 성공적인 분야로 꼽힘
이미지에서의 객체 인식률은 이미 사람의 수준에 버금가고, 중국어와 영어를 동시에 인식하는 기술이 소개됐으며, 필기체 인식은 99%에 육박하여 우편물 자동화 처리에 이미 적용 중
글로벌 IT기업의 행보 – 인공지능에 대한 공격적인 투자와 연구개발
구글은 이미 검색 알고리즘에 인공지능을 접목시켰고, 페이스북은 97%의 정확도로 사진에서 사람의 얼굴을 인식하며, 아마존에서는 로봇을 활용하여 물류시스템을 제어
인공지능의 성공 요인
컴퓨팅 환경의 고도화
그간 컴퓨터 연산처리장치는 지수적인 성능 향상을 달성하며 발전했으며, 실리콘칩의 대량생산 기조에 따라 고성능 저비용 연산처리장치 보급이 확산
• 현재 스마트폰에 탑재된 AP(Application Processor)의 GPU(그래픽연산처리장치, Graphical Processing Unit)는 약 265 Giga FLOP/s(1)의 이론 성능을 보유
• 1996년 6월 발표된 세계 1위 슈퍼컴퓨터 SR2201/1024의 실측성능은 약 220 Giga FLOP/s로 스마트폰의 GPU의 이론 성능에 육박
20년 전 약 500억 원에 달하는 슈퍼컴퓨터가 손안에 들어온 시대 도래했음에도 불구하고 학습기반의 인공지능 연구에는 여전히 막대한 계산량이 필요
• 예를 들어 딥러닝 기술은 신경망 구성에 대한 이론이나 원칙이 경험적으로 짐작(Rule of Thumb)되기 때문에 많이 시도해보는 것이 중요
• 바둑 인공지능 프로그램 AlphaGo의 기보학습에는 약 3주간의 시간동안 50장의 그래픽카드를 활용 하여 계산했는데, 이 결과를 얻기까지 수 천, 수 만 번의 반복 계산이 필요
빅데이터의 대중화
제4차 산업혁명에서의 데이터의 중요성은 언급을 하지 않아도 될 정도로 공감대가 형성
• 인터넷을 통한 데이터의 보급은 새로운 먹거리를 창조할 뿐만 아니라 지능적 의사결정을 위한 인공지능 연구에도 활용
• 빅데이터 여론 분석을 통해 기업의 이미지와 상품의 피드백을 추측할 수 있으며, 타겟형 소비자 매칭으로 영업 이익을 극대화하는 것이 현실적으로 가능
학습기반의 인공지능 분야에서는 자율 학습이 등장함에 따라 데이터를 재가공하기 위한 비용이 절감
• 기존의 감독학습(supervised learning)은 데이터와 대응 값이 1:1로 쌍을 이뤄야 했기 때문에 학습에 필요한 데이터 셋을 풍부하게 확보하는 것이 중요
• 그러나 자율학습에서는 대응 값이 필요하지 않기 때문에, 인공지능 분야에서 빅데이터의 대중화는 로켓엔진의 연료 역할을 하여 기술적 진화를 가속화
공개SW를 통한 공유의 확산
인공지능 및 기계학습 관련 공개SW는 글로벌 IT 기업과 유수의 대학 연구진이 주도적으로 개발하여 현재까지 약 42종에 달함
공개SW의 힘으로 인공지능 연구의 진입장벽이 현저히 낮아짐
• 최신 연구결과가 집단지성을 통해 공유되어 연구자들은 데이터를 확보하여 모델링하는 업무에 집중 가능
• GPU와 같은 고성능 계산자원 역시 병렬화 과정이 모두 구현되어 컴퓨팅 인프라를 십분 활용할 수 있는 환경이 조성됨
(1) FLOP(부동소수점연산수, Floating point Operation)은 연산수를 나타내는 단위로 연산처리장치의 성능을 측정하는 지표로 사용됨. FLOP/s(초당 부동소수점연산수)는 1초에 얼마나 많은 연산을 처리 할 수 있는지를 나타내는 것으로 슈퍼컴퓨터의 성능비교 등에 적용