심층학습(Deep Learning)의 장점과 단점
- (장점) 심층학습은 현대 인공지능 기술의 핵심으로 대규모 데이터를 학습하여 패턴을 인식하거나 미래를 예측하는 데 활용
- 구글 딥마인드가 개발한 인공지능 바둑 프로그램 알파고는 13층의 합성곱 신경망*, 40층의 잔차 신경망**을 활용해 바둑 지식을 학습
- * 합성곱 신경망(Convolutional Neural Network)은 이세돌 9단과 대결한 알파고 버전으로 16만 개의 바둑 기보를 학습한 인공신경망
- ** 잔차 신경망(Residual Neural Network)은 인간의 바둑 기보 없이 스스로 대국하여 최정상 바둑실력을 증명한 알파고제로가 활용한 인공신경망 구조
- 사진 분류 성능을 시험하는 CIFAR-10* 데이터셋 기준 예측 오차율은 2017년 기준 2.56%(DenseNet + CutOut)
- * Canadian Institute For Advanced Research의 약어로 6만 장의 사진을 10개의 종류로 구분한 이미지 데이터로, 심층학습 분야에서 이미지 분류 성능을 측정하는 기준 데이터로 활용됨
- 언어 모델을 시험하는 Penn Treebank* 데이터셋 기준 혼잡도(Perplexity)는 2018년 기준 56.0을 기록(Long Short-Term Memory(LSTM) 활용)
- * Penn Treebank는 문장을 형태소 별로 구분한 말뭉치 데이터셋으로 언어 모델의 성능(주어진 문장의 다음에 올 단어 예측)을 측정하는 데 활용
- (단점) 심층학습은 성공적인 학습을 위해 방대한 양의 데이터가 필요하고, 높은 예측 성능에 대한 설명이 거의 불가능하며, 이로 인해 실험을 통한 경험적 결과에 의존
- 심층학습에서는 데이터의 절대량이 예측 성능과 직결될 가능성이 높으며, 상대적으로 빈도가 낮은 경우*를 성공적으로 예측하기 위해서는 더욱 많은 데이터를 필요로 함
- * 자연재해, 보험 사기, 비정상적인 금융 거래 등 현상 자체가 빈번하게 일어나지 않는 분야를 예측하는 경우
- 심층학습으로 현상을 예측하는 인공신경망 모델이 왜 예측을 잘 하는지에 대한 설명 가능성*이 낮음
- * 이 부분을 극복하기 위해 현재 미국의 방위고등연구계획국(DARPA)에서는 막대한 예산을 투입하여 설명 가능한 인공지능(Explainable AI) 연구를 진행 중
- 심층학습의 결과물인 인공신경망 모델은 그 구조가 경험적으로 얻어진 것이 일반적으로, 보다 많은 경우의 수를 상정하여 시도한 최적의 결과
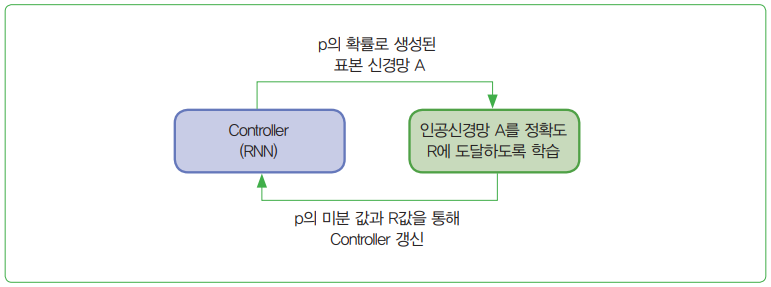
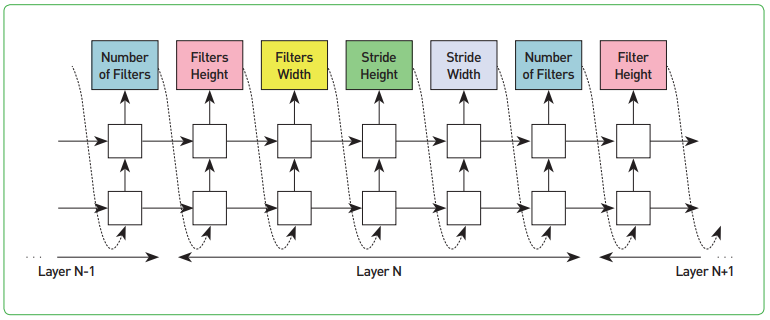
- 신경망 구조 탐색(Neural Architecture Search, NAS) 기술은 앞서 기술한 심층학습의 세 번째 단점인 인공신경망 구조를 찾는 과정을 다시 심층학습으로 찾아내는 과정으로, 학습하는 방법을 학습하는 방법론으로 부상