인공지능 안전에 대한 미국 정부와 EU의 논의 동향
- 트럼프 대통령은 2019년 2월 ‘인공지능 분야에서 미국의 리더십 유지’라는 행정명령을 발표하고 5대 원칙을 제시했다. 트럼프는 5대 원칙 중 하나로 인공지능 시스템에 적합한 ‘기술 및 안전 표준’을 개발하도록 미국표준기술연구소(NIST)에 요청하였고 그에 따라 NIST는 ‘기술 표준 및 관련 도구 개발에 대한 연방 정부의 계획’초안을 발표하였다. NIST 보고서에서 인공지능 안전을 위한 각 기관의 노력으로써 미국 교통국(DOT)의 ‘미래 교통의 준비 : 자율주행차 3.0(Preparing for the Future of Transportation : Automated Vehicles 3.0)’과 식품의약국(FDA)의 ‘인공지능/기계 학습(AI/ML)기반 의료기기 소프트웨어(SaMD) 수정을 위한 규제 프레임워크’를 소개하고 있다.
- FDA 보고서를 살펴보면 질병의 치료, 진단, 완화 또는 예방하기 위한 목적의 AI/ML 기반 소프트웨어를 의료기기로 정의하고, 이를 ‘AI/ML기반 SaMD(이하 SaMD)’로 명명했다. 적절한 규제 감독을 통해 안전하고 효과적인 소프트웨어 기능을 제공할 때 SaMD가 의료기기로서 역할이 가능하다고 한다. 안전한 SaMD 구현을 위해서 소프트웨어의 위험 수준을 정하고 위험이 일정 수준 이상인 소프트웨어의 사전검증이 시행된다. 사전검증은 소프트웨어 개발 전체 주기(TPLC, Total Product Life Cycle)에서 시행된다. TPLC 접근법은 시판 전 개발에서 시판 후 성과에 이르기까지 소프트웨어 제품의 평가 및 모니터링을 가능하게하고 해당 SaMD제품사의 탁월성에 대한 지속적인 검증을 가능하게 한다.
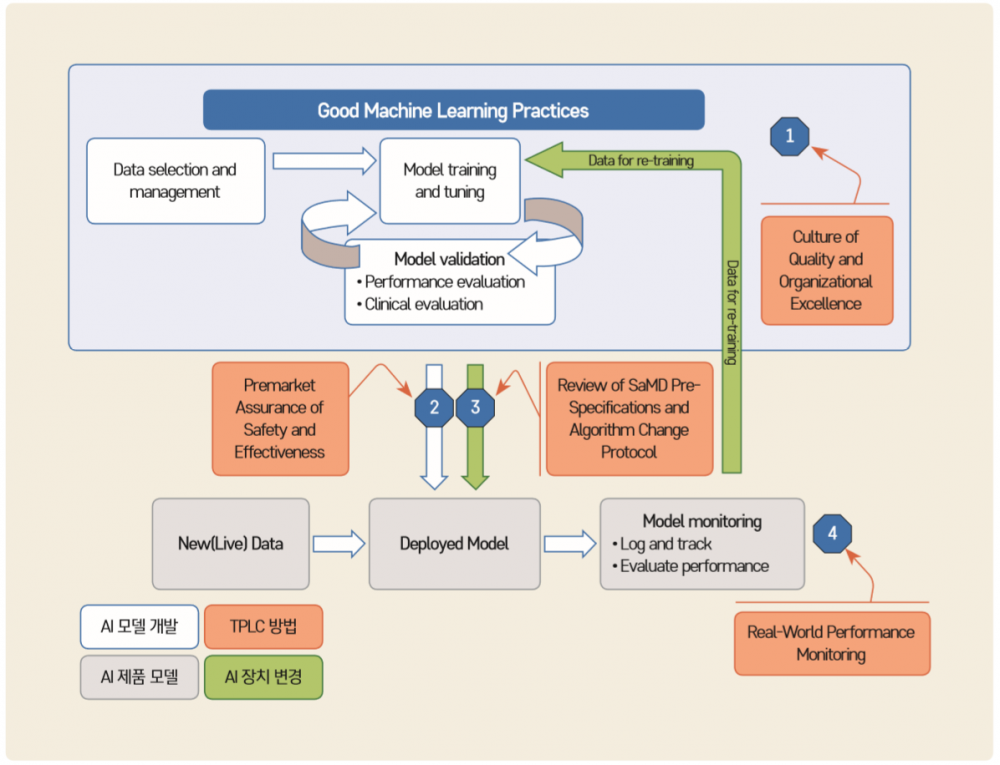
- 다음 그림은 안전한 의료 소프트웨어 제품을 개발하는 방법을 도식화한 것이다. 제조회사의 품질 및 안전 목표에 따라 인공지능 모델을 개발한다. 이러한 모델은 안전과 유효성에 대한 시판 전 검증과 제품 변경 시 재검증을 통하여 안전을 확보한 제품으로 개발된다. 개발된 제품은 시판 후에도 검증을 통하여 안전과 제품 성능을 확보한다.
-
그림 4 인공지능/머신러닝 개발에 관한 FDA의 전체 생명주기 방법 적용
※ 자료 : FDA(2019), Proposed Regulatory Framework for Modification to Artificial
Intelligence/Machine Learning (AI/ML) based Software as a Medical Device(SaMD)
※ 주 : 1. 제품 품질에 대한 목표 설정, 2. 안전과 유효성에 대한 시판 전 검증, 3. SaMD와 알고리즘 변경에 대한 검증, 4. 현실 세계에서 검증
- 한편, 유럽연합집행위원회(EC)에서는 2019년 4월 ‘신뢰할 수 있는(Trustworthy) 인공지능을 위한 윤리지침’을 발표했다. 신뢰할 수 있는 인공지능을 개발하고 사용하기 위한 7가지 요구사항 중 하나가 기술적 ‘안전성’이다. 신뢰할 수 있는 인공 지능을 달성하는 데 중요한 구성 요소는 위해(Hazard) 예방을 구현하는 기술적인 견고성이다. 의도하지 않은 위험을 최소화하고 허용 가능한 수준으로 위험을 방지함으로써 인공지능 시스템이 안정적으로 작동되도록 개발되는 것이 기술적 견고성이다. 이를 통해 사람의 신체적, 정신적 안전을 보장한다.
- EC 보고서는 인공지능 안전은 대체계획, 기술적 안전성·정확성·신뢰성(Reliability)·재현성을 구현 함으로써 확보할 수 있다고 했다. 신뢰성은 정의된 입력과 상황 범위에서 올바르게 작동하는 것을 의미 한다. 재현성은 인공지능 실험이 동일한 조건하에서 반복될 때 동일한 행동을 보이는지 여부를 나타 낸다. 대체계획이란 인공 지능 시스템에는 문제가 생길 경우 대체가 가능한 안전장치를 추가하는 것이다. 이것은 인공지능 시스템이 통계에서 규칙 기반 절차로 전환하거나 행동을 계속하기 전에 인간 운영자의 개입을 요구한다는 것을 의미할 수 있다. 인공지능 안전 확보를 위해서는 종합적으로 시스템이 모든 생명체와 환경을 해치지 않고 작업을 수행하는지 검토되어야 하며 의도하지 않은 결과와 오류의 최소화를 구현해야 한다. 또한 다양한 응용 분야에 걸쳐 인공지능 시스템의 잠재적인 위험을 규정하고 평가하는 프로세스가 수립되어야 한다. 이러한 대체계획, 기술적 안전성, 정확성, 신뢰성, 재현성은 인공지능 시스템의 위험이 높을수록 완성도가 높아야 한다.