2. 슈퍼컴퓨터를 둘러싼 미·중 기술패권 경쟁
- 현재 슈퍼컴퓨터의 가장 큰 도전과제는 엑사스케일 컴퓨팅이다. 이 목표에 가장 근접한 국가는 미국과 중국이다. 중국은 2017년 자체기술만으로 세계 정상을 차지한 선웨이 타이후라이트의 기술력을 바탕으로 2020년까지 엑사스케일 슈퍼컴퓨터를 구축하겠다고 선언했다. 슈퍼컴퓨터의 종주국이자 요람이라 할 수 있는 미국은 2021년에 엑사스케일을 달성하겠다고 청사진을 내놓은 상황이다. 슈퍼컴퓨터 정상의 자리 역시 미국과 중국이 엎치락뒤치락하는 가운데 슈퍼컴퓨터를 둘러싼 미·중의 기술패권 경쟁이 심화되고 있다.
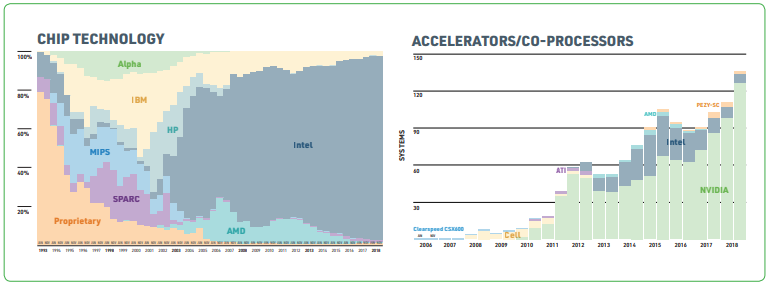
- 미국은 사실상 전 세계의 슈퍼컴퓨터를 공급하는 나라다. 연산처리장치의 주요 생산업체인 Intel, NVIDIA, AMD, IBM 등 대다수의 기업이 미국에 포진돼 있다. 또한 미국의 주요 주립대나 대부분의 국가 연구소는 슈퍼컴퓨터 시스템을 구축하고 있으며, 보안상의 이유로 슈퍼컴퓨터 목록에 등재되지 않은 자원도 많이 있다. 특히 구글, 페이스북 등 미국의 글로벌 IT기업은 자신의 컴퓨팅 파워를 노출하는 것을 꺼려하여 슈퍼컴퓨터 등재 자체를 하지 않는다. 이러한 사실을 바탕으로 보면 미국의 잠재적인 컴퓨팅 파워는 막대할 것이다. 미국은 중국의 급격한 추격에도 흔들리지 않는 견실함이 있다고 볼 수 있다. 또한 중국이 자체기술로 개발한 선웨이 타이후라이트는 놀라운 결과이긴 하지만 미국의 아성을 넘기는 힘들다는 견해가 있다. 그 이유는 슈퍼컴퓨터에서 전통적으로 활용되는 Intel이나 NVIDIA의 연산처리장치에서 찾아볼 수 있다. 그림 4에서 볼 수 있듯이, 연산처리장치와 가속기의 비중은 모두 미국 기업이 선점하고 있다.
-
그림 4 연도별 연산처리장치의 생산기업 변화(좌), 연도별 가속기 생산기업 변화(우)
※ 자료 : TOP500 The list https://www.icl.utk.edu/files/print/2018/top500-sc18.pdf
- 중국은“수치상”으로는 미국에 근접한 슈퍼컴퓨터 보유국이다. 지난 2017년에는 국가별 top500 목록의 슈퍼컴퓨터 보유율에서 중국이 미국을 앞섰을 뿐만 아니라, top1 머신도 중국의 선웨이 타이후라이트였다. 이러한 관점에서 봤을 때 중국이 미국을 위협한다는 분석은 일견 설득력 있어 보인다. 또한 중국 정부의 슈퍼컴퓨터에 대한 투자 의지는 매우 강력하다. 미국이 연산처리장치 수출을 제재함에 따라 중국 역시 자생해야 하는 숙제가 생겼기 때문이다. 그러나 중국이 처해있는 상황은 녹록지 않다. 먼저 미국과 그 우방국의 지지 없이 자국의 연구진만으로 기술격차를 해소하기에는 어렵다는 관점이다. 물론 선웨이 타이후라이트가 성공했지만, 사실 문제는 그 이후다. 또한 미국에 버금가는 중국의 슈퍼컴퓨터 보유율에는 허수가 있다. 미국은 글로벌 IT기업이 등재하지 않는 분위기인 반면, 중국은 IT기업도 적극적으로 등재하고 있다. 이러한 사실로 볼 때 중국을 미국과 대등한 슈퍼컴퓨터 강국으로 보기는 어렵다.
- 선웨이 타이후라이트에 탑재된 연산처리장치인 SW26010은 Intel이나 NVIDIA의 연산처리장치와는 구조적으로 다르다. 따라서 Intel이나 NVIDIA 기반으로 개발된 수치 라이브러리를 모두 SW26010에 성공적으로 이식시켜야 본격적인 경쟁이 가능하다. 거의 50년 가까이 누적된 알고리즘의 최적화를 SW26010에 구현한다는 것은 중국의 노력만으로는 사실상 불가능하다. SW26010을 많이 활용할 수 있는 연구 생태계 확보가 불가능하다면 사실상 미국과 직접 대결하기는 어렵다. 그러나 한편으로는 중국의 위협이 무섭다는 판단도 있다. 중국은 거대한 내수 시장이 있다. 중국이 자체적으로 개발한 슈퍼컴퓨터를 중국 내부에서 활용하는 생태계를 조성한다면 기술의 격차가 현격히 좁아질 수 있다는 입장이다.
- 미국과 중국의 슈퍼컴퓨팅 기술 경쟁은 사실상 과학기술의 리더를 경쟁하는 자리라고 볼 수 있다. 여러 사실들을 종합해 보면, 중국이 미국을 위협한다는 것은“수치상”일 뿐이지 현실은 그렇지 않을 수 있다. 그러나 수치상으로 미국을 앞선다는 사실은 중국의 기술력이 그만큼 앞서 있다는 착시를 줄 수 있기 때문에, 기술패권을 경쟁한다는 구도로 보일 수도 있다.
- 지난 2015년 미국의 대중 연산처리장치 수출제재는 결국 미국이 승리했다고 본다. 미국은 유럽 및 일본과 같은 슈퍼컴퓨터 강국과 우호적인 관계를 이어오고 있다. 그 연구 생태계도 마찬가지다. 슈퍼컴퓨터에서 미국과 중국의 대결은 미국, 유럽, 일본과 중국의 대결 구도다. 중국이 급성장하고 막대한 투자를 이어가고 있기는 하나 기존의 생태계를 흔들 수 있는 것은 아니다.
- 정리하자면 중국은 최단 기간 안에 미국에 수치상으로 대등한 슈퍼컴퓨터를 보유했다. 그러나 그 기술력의 차이는 여전히 존재하는 것으로 판단된다.