| 구 분 | 바 둑 | 스타크래프트2 |
|---|---|---|
| 장르 | 보드게임 | 실시간 전략 시뮬레이션 |
| 게임 진행 | 턴 방식 | 실시간 명령 |
| 게임 공간 | 19×19 격자 공간 (총 361개) |
한 스텝의 행동 기준 108가지의 조합 공간 |
| 소요 시간 | 1 ∼ 4시간 | 10분 ∼ 1시간 |
| 상대방의 상황 | 모두 공개 | 정찰을 통해 습득 |
| 도전과제 | 내 용 |
|---|---|
| 게임 이론 | ▪ 가위-바위-보 게임과 같이 하나의 최상의 전략은 없음 |
| 불완전한 정보 | ▪ 상대방의 정보는 정찰이라는 수단을 통해 획득 ▪ 스타크래프트2의 전략은 상대방의 정보를 바탕으로 자신의 전략을 수정 및 고도화하는 방향으로 진행 |
| 장기 계획 | ▪ 실세계의 문제와 같이 원인과 결과가 즉각적으로 반영되지 않음 |
| 실시간 제어 | ▪ 연속적인 동적 조작을 통해 게임이 진행됨 ▪ 측정 기준으로는 분당 행동 수(Actions Per Minutes, APM)가 있음 |
| 넓은 조작 공간 | ▪ 하나의 행동을 결정하기 위해 산술적으로 약 108가지의 조합 공간을 가짐 ▪ 일반적으로 한 스텝당 유효한 일련의 행동을 선정해야 함 |
| 구 분 | 알파고 Lee | 알파스타 |
|---|---|---|
| 학습 데이터 | 16만 건의 대국 | 80만 건 이상의 리플레이 데이터 |
| 입력 (inputs) |
48개의 특성으로 나눠진 기보 (예 – 흑돌, 백돌, 빈칸 위치, 단수, 축, 꼬부림 등) |
PySC26를 활용한 이미지 데이터 (예 – 현재 시야, 건물, 유닛 등) |
| 출력 (outputs) |
착수 가능 지점의 확률, 승리할 확률 |
일련의 행동(10개 ~ 26개), 승리할 확률 |
| 학습 방법 | 기보를 통한 지도학습과 자체 대결을 통한 강화학습 |
리플레이 데이터의 지도학습과 자체 대결을 통한 강화학습 |
| 학습 구조 (architecture) |
합성곱신경망, 몬테-카를로 트리 탐색 (MCTS) |
합성곱신경망, 장단기기억(LSTM), 어텐션, 포인터네트워크 등 |

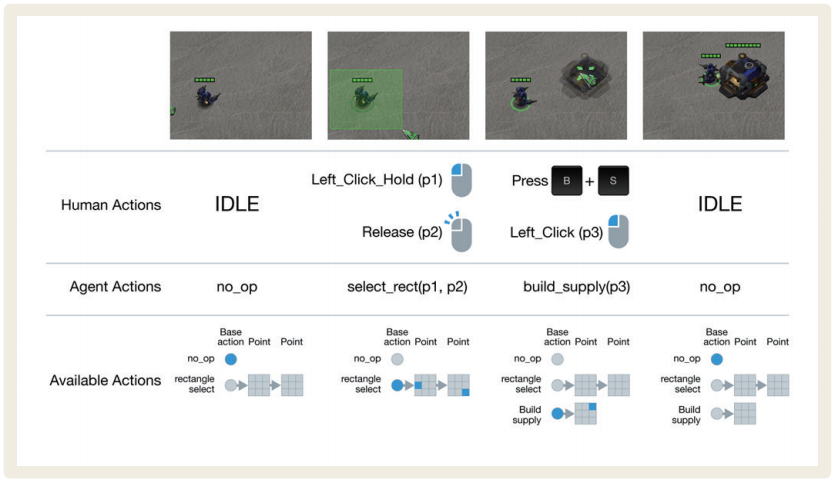
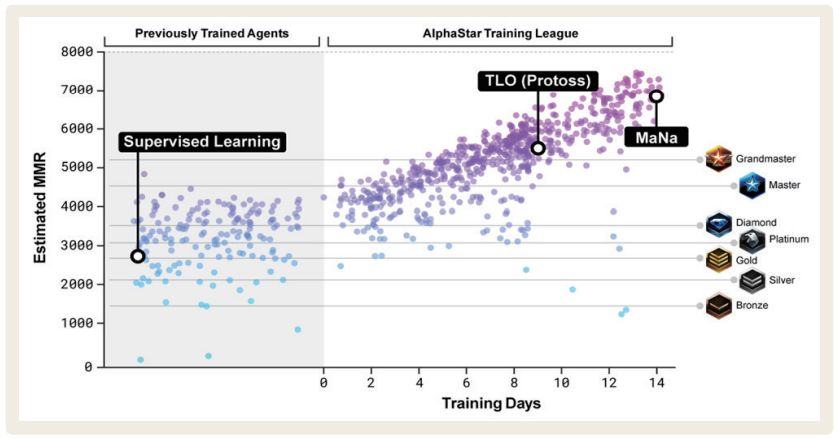
| 구 분 | 알 고 리 즘 |
|---|---|
| 리플레이 데이터 학습 | Transformer, LSTM, Auto-regressive policy head, Pointer network, Centralised value baseline |
| 알파스타 리그 학습 | Population-based reinforcement learning, Multi-agent reinforcement learning, Off-policy actor-critic, Experience replay, Self-imitation learning, Policy distillation, Nash distribution of the league |
경기도 성남시 분당구 대왕판교로 712번길 22 글로벌 R&D센터 연구동 B 4층 개인정보처리방침
Copyright © 2014-2021 By Software Policy & Research Institute.
All rights reserved.


|
|
| 항목 | 수집목적 | 보유기간 |
|---|---|---|
| 이메일 | SPRi 뉴스레터 발송, 신규 콘텐츠, SPRi 소식 등 제공 | 수신거부 시 까지 |
|
|