| 구분 | 원인 | 예시 |
|---|---|---|
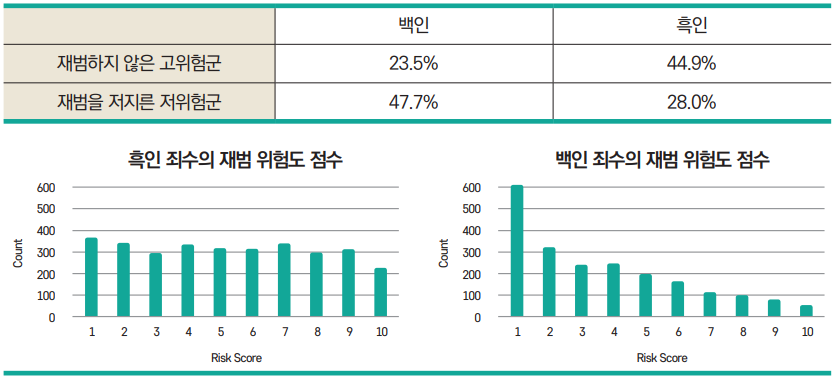
| 관측되지 않은 성능 차이 | 치우친 표본 | 초기 범죄율이 높은 곳으로 더 많은 경찰관을 파견하는 경향이 있고, 그러한 지역에서 범죄율에 대한 기록이 더 높아질 확률이 높음 |
| 오염된 사례 | 구글 뉴스 기사에서 남성-프로그래머의 관계는 여성-주부와의 관계와 매우 유사한 것으로 밝혀짐(Bolukbasi et al., 2016) | |
| 관측된 성능 차이가 존재하는 표본의 복제 | 제한된 속성 | - |
| 표본 크기의 불일치 | - | |
| 예측 결과의 불일치 | 대리 변수의 존재 | 인종, 성별과 같은 민감한 속성에 대해 이웃과 같은 속성이 대리 변수로서 작용하여 예측 결과가 편향될 수 있음 |
| 구분 | 정의 | 수학적 정의 |
|---|---|---|
| 예측결과 기반 | 그룹 공정성 (통계적 동등성, 동등한 승인율) | 그룹별로 긍정적 예측값을 할당받을 확률이 동일 |
| 조건부 통계적 동등성 | 특정 데이터 속성(요소)을 통제했을 경우 그룹 별로 긍정적 예측값을 할당받을 확률이 동일 | |
| 예측·실제결과 기반 | 예측적 동등성 결과 동등성 | 그룹별로 긍정적 예측값의 비율이 실제로 동일해야 함 |
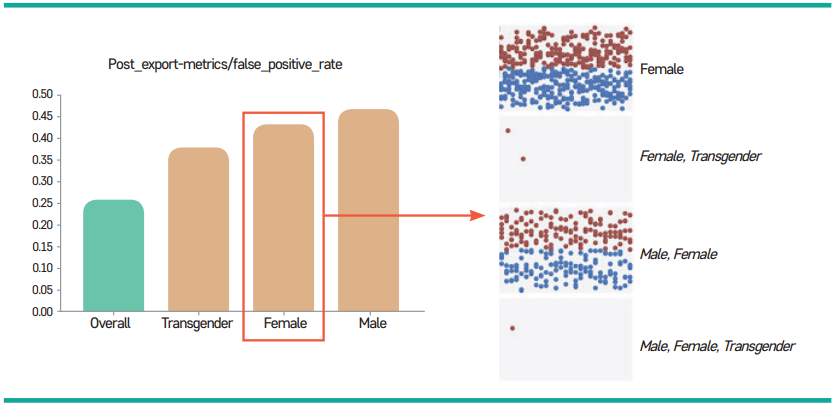
| 위양성율(Type I Error/ False Positive Error Rate) 균형 | 그룹별로 위양성 예측값을 할당받을 확률이 동일 | |
| 위음성율(Type II Error/ False Negative Error Rate) 균형 | 그룹별로 위음성 예측값을 할당받을 확률이 동일 | |
| 동등확률 | 그룹별로 실제 값 기반 진양성율(TPR, True Positive Rate)과 위양성율(FPR, False Positive Rate)은 동일 | |
| 조건부 사용 | 정확도 동등성 그룹별로 예측 값 기반 양성예측도(PPV, Positive Predictive Value)와 음성예측도(NPV, Negative Predictive Value)가 동일 | |
| 전체 정확도 동등성 | 그룹별로 전체적인 예측 정확도(진양성: True Positive, 진음성: True Negative)가 동일 | |
| 치료 동등성 | 그붑별로 위양성(False Positive)과 위음성(False Negative)의 비율이 동일 |
| 구분 | 예시 |
|---|---|
| 개념 정의의 한계 | 단일한 최상의 수학적 개념 정의가 되지 않음 |
| 모순적 공정성 개념의 공존 | 통계적 공정성(그룹 공정성, 예측적 패리티, 동등확률)의 요건들이 동시에 만족되기 어렵다는 제약 조건 |
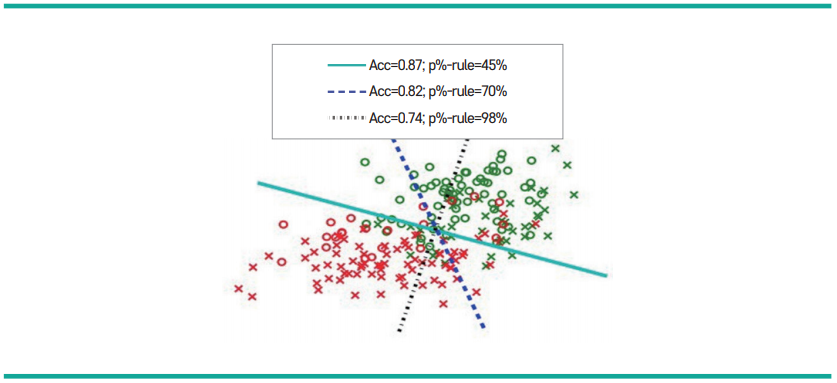
| 예측의 정확도와 절충 관계 | 공정성을 높이면 정확도가 떨어지는 경향 |
| 분배적 공정성에 종속 | 통계적 공정성은 분배적 관점에서 정의되고 있으며, 절차적 공정성이 갖춰지면 높아질 수 있는 가능성이 있으나, 일반적으로 통계적 공정성이 있어도 절차적 공정성이 있다고 볼 수는 없음 |
경기도 성남시 분당구 대왕판교로 712번길 22 글로벌 R&D센터 연구동 B 4층 개인정보처리방침
Copyright © 2014-2021 By Software Policy & Research Institute.
All rights reserved.


|
|
| 항목 | 수집목적 | 보유기간 |
|---|---|---|
| 이메일 | SPRi 뉴스레터 발송, 신규 콘텐츠, SPRi 소식 등 제공 | 수신거부 시 까지 |
|
|