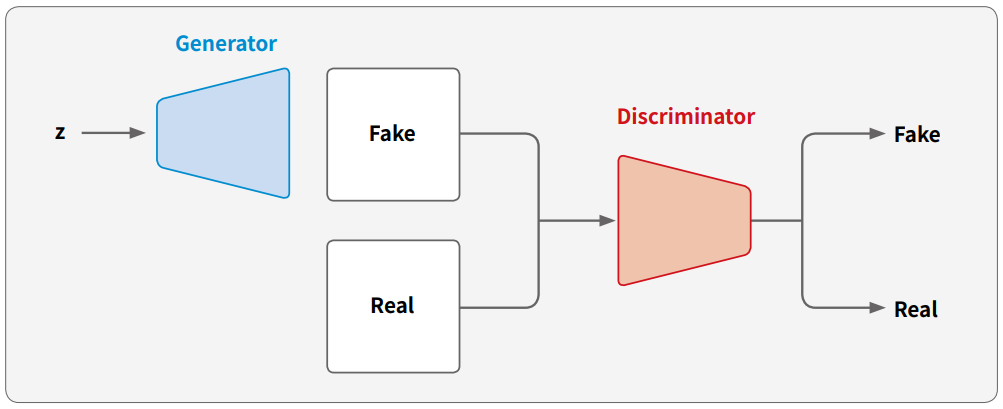
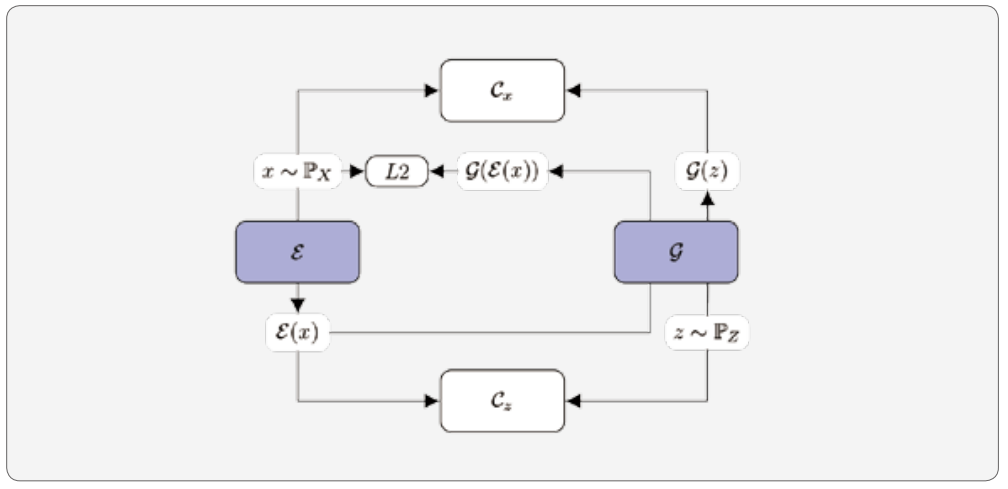
| 생성자 | ε(인코더) | 시계열 시퀀스(x) → 잠재 변수(z) |
|---|---|---|
| g(디코더) | 잠재 변수(z) → 시계열 시퀀스(g(z)) | |
| 판별자 | Cx | 시계열 시퀀스(x)와 g(z)의 판별 |
| Cz | 잠재 변수(z)의 매핑 정도 |
경기도 성남시 분당구 대왕판교로 712번길 22 글로벌 R&D센터 연구동 B 4층 개인정보처리방침
Copyright © 2014-2021 By Software Policy & Research Institute.
All rights reserved.


|
|
| 항목 | 수집목적 | 보유기간 |
|---|---|---|
| 이메일 | SPRi 뉴스레터 발송, 신규 콘텐츠, SPRi 소식 등 제공 | 수신거부 시 까지 |
|
|