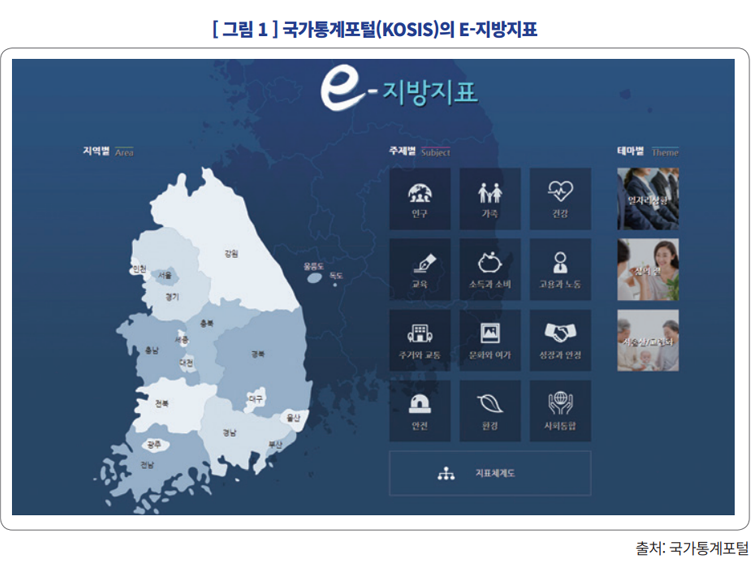
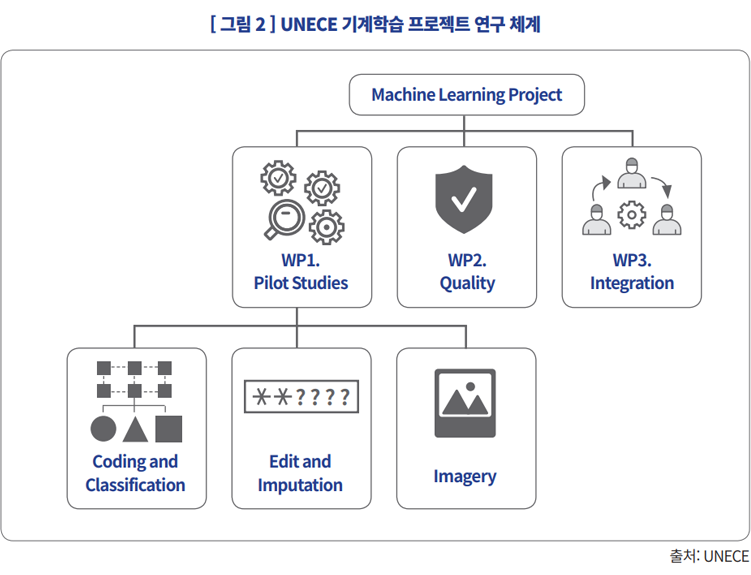
| 주제 | 국가 | 세부주제 |
|---|---|---|
| 코딩 및 분류 (C&C) | 멕시코 | 자연어 처리를 활용한 직업 및 경제 활동 코딩 |
| 캐나다 | 산업 및 직업 분류체계 코딩 | |
| 벨기에 | 트위터 데이터의 감정 분석 | |
| 세르비아 | 노동력 조사에서 수집한 경제 활동에 관한 비정형 데이터 코딩 | |
| 미국 | 직장 상해 및 질병 코드 분류 | |
| 폴란드 | ECOICOP8에 대한 설명 데이터 코딩 | |
| IMF | IMF의 시계열 카탈로그를 활용한 자동 코딩 | |
| 아이슬란드 | 사회 통계 조사에서 직업 및 산업의 자동 코딩 | |
| 노르웨이 | 표준 산업 코드 자동화 분류 | |
| 편집 및 표본대체 (E&I) | 이탈리아 | 개인 기본 등록부에서 “교육 수준 달성”변수의 표본대체 |
| 폴란드 | 폴란드 거주 인구에 대한 표본 조사의 표본대체 | |
| 독일 | 표본대체를 위한 기계학습 알고리즘 전반 검토 | |
| 벨기에 | 기계 학습을 사용한 에너지 잔량 통계의 조기 추정법 | |
| 캐나다 | 에너지 잔량의 조기 추정을 위한 시계열 모델 | |
| 영국 | 생활비 조사 소득 데이터 편집 | |
| 이탈리아 | 이탈리아 행정통계 편집 | |
| 이탈리아 | NSI9의 데이터 편집 및 정리를 위한 기계 학습 | |
| 이미지 분석 (E&I) | 호주 | 자동 이미지 인식 (AIR) 모델 개발 |
| 네덜란드 | 이미지에서 통계 정보 학습 : 개념 증명 | |
| 스위스 | Arealstatistik Deep Learning(ADELE) 개발 | |
| 멕시코 | Landsat 위성 데이터 분석을 통한 도시 지역 인구 매핑 | |
| UNECE | 위성 데이터 및 기계 학습을 사용하여 국가통계를 생성하기 위한 일반적인 파이프라인 제시 |
| 연구기획 | 목표단계 | 아이디어→유효한 솔루션(시범) | 아이디어→유효한 솔루션(운영) | 생산견고성 보장(유지보수) | ||||
|---|---|---|---|---|---|---|---|---|
| (~'20) | 모든 분야의 시범 연구 | 일부 분야의 시범 연구 | - | |||||
| 기타 기계학습 어플리케이션 | 기타 기계학습 어플리케이션 | |||||||
| 통계 생산체계 통합 | 통계 생산체계 통합 | |||||||
| (~'21) | 서로 다른 통계 데이터의 레코드를 연계 매핑하는 연구 위성데이터 분석 고도화 등 | |||||||
| 지원방안 | 지원유형 | 품질 | 좋은 훈련데이터 | 기술/역량 | 컴퓨팅 인프라 | 상호 운용성/절차 | 윤리 및 법률 | 보안 |
| (~'20) | 품질평가 | 통계 생산체계 통합 | ||||||
| (~'21) | • QF4SA의 실질적인 도입방향성 도출 |
• 양질의 데이터습득 방법 • 데이터 상태를 최신 상태로 유지하는 방법 • 모델 재학습 시기 • 양질의 기준 정립 및 품질 측정방법 |
• 기술의 정의 • 교육방법 마련 |
미정 | 미정 | 윤리가이드라인 및 규정 재정 | 미정 | |
| • QF4SA 프레임워크 검토 및 개선 | ||||||||
| 촉진방안 | 유형구분 | 조직 | 공유 및 협업 | |||||
| (~'20) | 통계 생산체계 통합 | HLG-MOS 기계학습 프로젝트 | ||||||
| (~'21) | • 기계 학습 솔루션의 통합을 가속화하기 위한 이니셔티브 | ML 연구 및 코드 | ||||||
| • 데이터 과학의 리더 네트워크 구축 | 교육 훈련 | |||||||
|
• 향후 2~5년을 어떻게 더 잘 준비할 수 있을지 • 향후 어떤 기술과 데이터 원천을 기대할 수 있는가 • 어떤 기술이 필요한가 |
HLG-MOS ML 프로젝트 웨비나 | |||||||
경기도 성남시 분당구 대왕판교로 712번길 22 글로벌 R&D센터 연구동 B 4층 개인정보처리방침
Copyright © 2014-2021 By Software Policy & Research Institute.
All rights reserved.


|
|
| 항목 | 수집목적 | 보유기간 |
|---|---|---|
| 이메일 | SPRi 뉴스레터 발송, 신규 콘텐츠, SPRi 소식 등 제공 | 수신거부 시 까지 |
|
|